こんな埼「玉」修正してやるぅ
Twitter を眺めていたら
総務省のマイナンバーカード交付状況をデータ化していて、データの結合がうまくいかないなーと思ったら、なんと、同じ埼玉でも文字コードが違うという落とし穴が・・
— Hal Seki (@hal_sk) July 11, 2020
3月8日では \u2f5f が使われていて、それ以降では\u7389…https://t.co/AOkV3iojaz pic.twitter.com/jU4P583Ad5
という tweet を見かけた。 これは Adobe Acrobat Distiller の不具合なんだそうで,2019年9月には既に話題に登っているのだが,2020年7月の時点でも修正されていないようだ。
Adobe Acrobat Distiller が見捨てられてるのか,それとも「日本語」が見捨てられているのか…
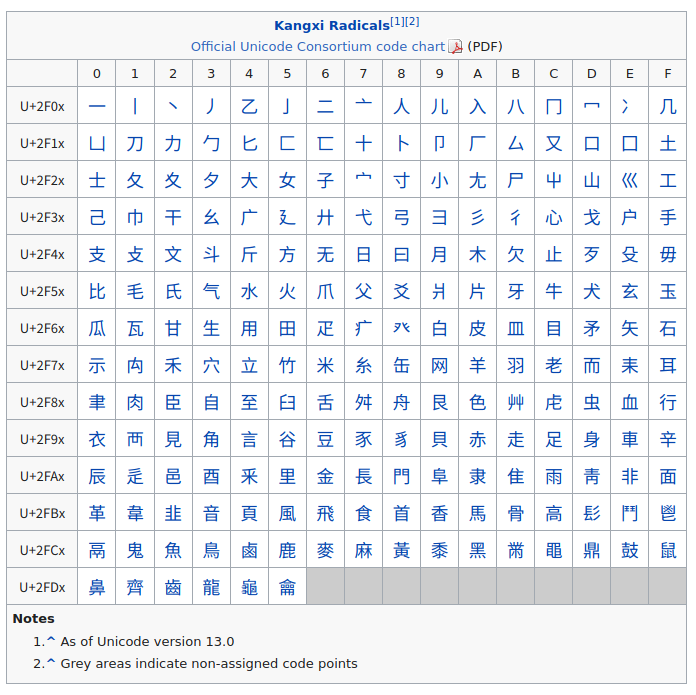
要するに,これらの領域の文字を本来の符号点に変換してやればいいわけだ。 件の tweet のスレッドを見ると,幸いにも Unicode の NFKC 正規化で変換可能らしい。
試しに以下のコードを組んで
package main
import (
"fmt"
"golang.org/x/text/unicode/norm"
)
func main() {
for r := rune(0x2f00); r <= 0x2fd5; r++ {
rr := []rune(norm.NFKC.String(string([]rune{r})))
if r != rr[0] {
fmt.Printf("%#U -(NFKC)-> %#U\n", r, rr[0])
}
}
}
実行してみると
$ go run sample1.go
U+2F00 '⼀' -(NFKC)-> U+4E00 '一'
U+2F01 '⼁' -(NFKC)-> U+4E28 '丨'
U+2F02 '⼂' -(NFKC)-> U+4E36 '丶'
...
U+2F5F '⽟' -(NFKC)-> U+7389 '玉'
...
U+2FD4 '⿔' -(NFKC)-> U+9F9C '龜'
U+2FD5 '⿕' -(NFKC)-> U+9FA0 '龠'
てな出力(一部割愛)になって,ちゃんと変換されていることが分かる。
ただし Unicode 正規化は副作用があるので安直には使えない。 となると,前回の「かなカナ変換」で紹介した方法が使えるかな。
変換後の符号点の値は散らばっていて且つ数も多く手作業でコードを書くのは不毛なので,まずは unicode.SpecialCase を生成するコードを書いてみよう(笑)
package main
import (
"fmt"
"strconv"
"golang.org/x/text/unicode/norm"
)
func main() {
fmt.Println("var KangxiRadicals = unicode.SpecialCase{")
for kr := rune(0x2f00); kr <= 0x2fd5; kr++ {
rr := []rune(norm.NFKC.String(string([]rune{kr})))
if kr != rr[0] {
fmt.Printf("\tunicode.CaseRange{%#[1]x, %#[1]x, [unicode.MaxCase]rune{%#[2]x - %#[1]x, 0, 0}}, // %#[1]U -> %#[2]U\n", kr, rr[0])
}
}
fmt.Println("}")
}
これを実行するとこんなコードが得られる(一部割愛)。
$ go run sample1b.go
var KangxiRadicals = unicode.SpecialCase{
unicode.CaseRange{0x2f00, 0x2f00, [unicode.MaxCase]rune{0x4e00 - 0x2f00, 0, 0}}, // U+2F00 '⼀' -> U+4E00 '一'
unicode.CaseRange{0x2f01, 0x2f01, [unicode.MaxCase]rune{0x4e28 - 0x2f01, 0, 0}}, // U+2F01 '⼁' -> U+4E28 '丨'
unicode.CaseRange{0x2f02, 0x2f02, [unicode.MaxCase]rune{0x4e36 - 0x2f02, 0, 0}}, // U+2F02 '⼂' -> U+4E36 '丶'
...
unicode.CaseRange{0x2f5f, 0x2f5f, [unicode.MaxCase]rune{0x7389 - 0x2f5f, 0, 0}}, // U+2F5F '⽟' -> U+7389 '玉'
...
unicode.CaseRange{0x2fd4, 0x2fd4, [unicode.MaxCase]rune{0x9f9c - 0x2fd4, 0, 0}}, // U+2FD4 '⿔' -> U+9F9C '龜'
unicode.CaseRange{0x2fd5, 0x2fd5, [unicode.MaxCase]rune{0x9fa0 - 0x2fd5, 0, 0}}, // U+2FD5 '⿕' -> U+9FA0 '龠'
}
あとはこれを組み込んで使えばいいだけ。 たとえばこんな感じに使える。
func unicodePrint(s string) {
ss := []string{}
for _, r := range s {
ss = append(ss, fmt.Sprintf("{%#U}", r))
}
fmt.Println(strings.Join(ss, " "))
}
func main() {
saitama := "埼⽟"
unicodePrint(saitama)
unicodePrint(strings.ToUpperSpecial(KangxiRadicals, saitama))
}
これを実行すると
go run sample2.go
{U+57FC '埼'} {U+2F5F '⽟'}
{U+57FC '埼'} {U+7389 '玉'}
となる。 よーし,うむうむ,よーし。
ブックマーク
参考図書

- プログラミング言語Go (ADDISON-WESLEY PROFESSIONAL COMPUTING SERIES)
- Alan A.A. Donovan (著), Brian W. Kernighan (著), 柴田 芳樹 (翻訳)
- 丸善出版 2016-06-20
- 単行本(ソフトカバー)
- 4621300253 (ASIN), 9784621300251 (EAN), 4621300253 (ISBN)
- 評価
著者のひとりは(あの「バイブル」とも呼ばれる)通称 “K&R” の K のほうである。この本は Go 言語の教科書と言ってもいいだろう。と思ったら絶版状態らしい(2025-01 現在)。復刊を望む!